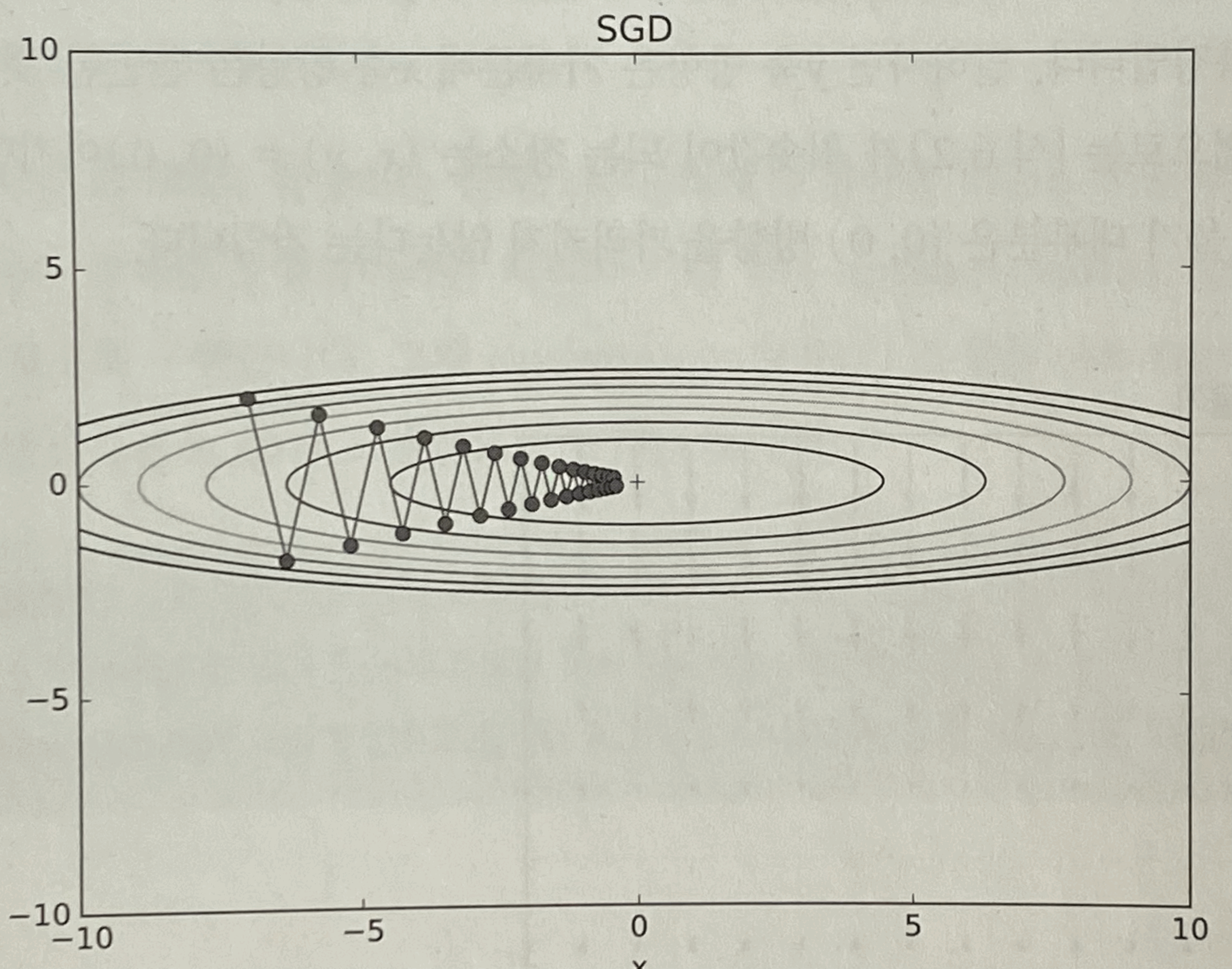
Lecture6: Training Neural Networks I- CS231n 강의 [1]를 듣고 공부한 내용을 나름대로 정리했다.- 글에 있는 모든 그림, 표, 예시는 [2]에서 가져왔다. ~ 목차 ~1. Activation Functions 1.1 Sigmoid 1.2 Tanh 1.3 ReLU 1.4 Leaky ReLU 1.5 ELU 1.6 Maxout 1.7 정리2. Data Preprocessing3. Weight Initialization 3.1 랜덤 초기화 3.2 특정 수로 초기화 3.3 Xavier 초기화 3.4 He 초기화4. Batch Normalization5. Babysitting the Learning Process ..