Lecture10: Recurrent Neural Networks
- CS231n 강의 [1]를 듣고 공부한 내용을 나름대로 정리했다.
- 글에 있는 모든 그림, 표, 예시는 [2]에서 가져왔다.
~ 목차 ~
1. 개념
2. Computational Graph
2.1 Many to Many
2.2 Many to One
2.3 One to Many
2.4 Sequence to Sequence: Many-to-one + One-to-many
3. 문제점 & 해결방안
3.1 Gradient Exploding → Gradient Clipping
3.2 Gradient Vanishing → LSTM3.3 BPTT → Truncated BPTT
4. Interpretable cell 탐색
5. 적용 예시
5.1 CV
5.2 NLP
1. 개념
- RNN은 Recurrent neural network의 약자로, 이전 정보를 기억할 수 있기 때문에 시간적 순서를 가진 데이터 처리에 적합하다.
- 기본적인 vanilla RNN은 아래와 같다.

- 벡터 $x_{t}$를 입력으로 넣어주면, 이전 단계의 은닉 정보 $h_{t-1}$와 함께 활성화 함수 $f_{W}$에 들어가서 새로운 은닉 정보$h_{t}$를 만든다.
즉, 새로운 은닉 정보 $h_{t}=tanh(W_{hh}h_{t-1}+W_{xh}x_{t})$ 가 생긴다.
- 이러한 $h_{t}$는 가중치 $W_{hy}$와 곱해져서 최종적으로 $y_{t}$로 출력된다.
- RNN은 아래와 같이 시퀀스를 입력과 출력의 데이터 길이에 따라 다양한 방식으로 처리할 수 있다.
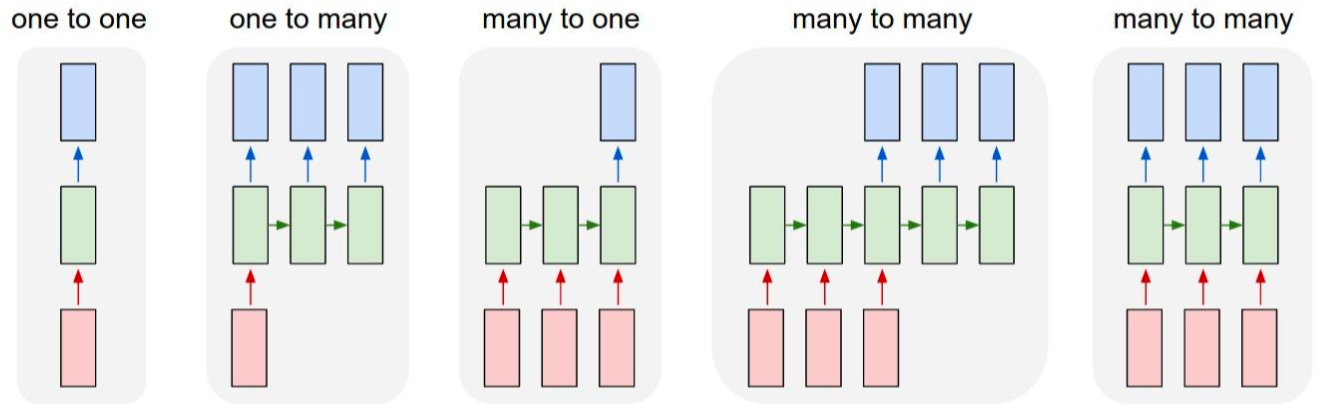
- 위에서 본 vanilla RNN은 가장 기본적인 one-to-one 구조에 해당한다.
- One-to-many는 입력 하나에 여러 개의 출력이 생성된다. (e.g. Image Captioning)
- Many-to-one은 입력 여러 개에 하나의 출력이 생성된다. (e.g. Sentiment Classification)
- Many-to-many는 입력 여러 개에 여러 개의 출력이 생성된다.
입력과 출력의 길이가 같을 수도 있고(e.g. Video classification on frame level) 다를 수도 있다 (e.g. Machine Translation).
2. Computational Graph
- RNN의 입출력 데이터 길이에 따른 computational graph는 다음과 같다.
2.1 Many to Many
- 먼저 many-to-many이다.
입력 벡터 $x_{t}$들과 이전 단계의 은닉 정보 $h_{t-1}$들이 함수 $f_{w}$를 통과해서 여러 개의 출력 $y_{t}$들을 만들고 있다.
이 출력들 각각의 loss function값 $L_{t}$를 구해서 모두 더하면 전체 loss값인 $L$이 나오게 된다.
이 과정에서 사용되는 가중치 $w$의 값은 모두 동일하다.

2.2 Many to One
- 다음으로 many-to-one이다.
입력 벡터 $x_{t}$들과 이전 단계의 은닉 정보 $h_{t-1}$들이 함수 $f_{w}$를 통과해서 전달되다가 최종적으로 하나의 출력 $y$를 만든다.

2.3 One to Many
- 다음으로 one-to-many이다.
처음에 입력 벡터 $x$가 은닉 정보 $h_{0}$와 함께 함수 $f_{w}$에 들어가면 새로운 은닉 벡터 $h_{1}$이 만들어지고, 이는 출력 $y1$으로 나오게 된다. 이후에는 은닉벡터 $h_{t}$만 쭉 전달되면서 여러 개의 출력 $y_{t}$를 생성한다.

2.4 Sequence to Sequence: Many-to-one + One-to-many
- 다음으로 Sequence to Sequence라고 불리는 Many-to-one + One-to-many이다.
크게 Encoder와 Decoder로 나눌 수 있는데, encoder에 있는 many-to-one 형태의 RNN에서 은닉 벡터 $h_{t}$가 나오면, 이게 그대로 one-to-many 형태의 decoder의 첫 은닉벡터로 들어가서 여러 개의 출력 $y_{t}$를 만들어낸다.

3. 문제점 & 해결방안
- RNN의 역전파 과정에서 발생하는 3가지 문제들을 살펴보고 이를 어떻게 해결할 수 있는지 알아볼 것이다.
3.1 Gradient Exploding → Gradient clipping
- Gradient Exploding은 RNN에서 역전파 도중 손실 값이 발산해버리는 현상이다.
아래 그림과 같이 RNN은 역전파 과정에서 시간 단계 1개마다 가중치 행렬 $W$가 곱해지는데, 이때 $W$값이 1보다 크면 발산하게 된다.

- 이 문제는 생각보다 단순하게 해결된다. Gradient Clipping을 사용해서 기울기의 크기를 임계값 이하로 제한하면 된다.
코드로 표현하면 아래와 같다.
grad_norm = np.sum(grad * grad)
if grad_norm > threshold:
grad *= threshold / grad_norm
3.2 Gradient Vanishing → LSTM
- Gradient Vanishing은 RNN에서 역전파 도중 손실 값이 0에 가까워지는 현상이다. $W$값이 1보다 작으면 이러한 현상이 발생한다.
이 문제는 RNN의 구조를 아예 바꾼 LSTM을 통해서 해결할 수 있다.
- LSTM은 Long short-term memory의 약자로, i,f,o,g 게이트들을 통해 중요한 정보를 기억하고 필요하지 않은 정보를 잊는다.
i는 Input gate, f는 Forget gate, o는 Output gate, g는 Gate gate (?) 이다.
다른 건 이름을 보면 추측이 가능하고, g gate는 이전 셀 상태 $c_{t-1}$에 얼마나 많은 새로운 정보를 추가할지 결정하는 게이트다.
그림과 수식으로 표현하면 아래와 같다.

- 먼저 이전 은닉상태 $h_{t-1}$과 입력 $x_{t}$가 stack되어서 가중치 행렬 $W$와 곱해진다.
그 다음에 각각 활성화 함수를 통과해서 f,i,g,o 게이트들로 들어가게 된다.
그리고 Forget Gate의 결과(삭제할 정보)와 Input Gate의 결과(추가할 정보)를 더해서 셀상태 $c_{t}$가 업데이트된다.
이렇게 업데이트 된 $c_{t}$는 o gate를 통해서 조정된 다음 활성화함수(여기서는 tanh)를 거쳐서 현재 은닉상태 $h_{t}$가 생성된다.
- 이렇게 만들어진 LSTM 구조는 역전파 단계에서 Gradient Vanishing 문제를 완화할 수 있다!
역전파 단계에서는 셀상태들이 f gate를 통해서 선형적인, 즉 직접적인 경로로으로 전달되기 때문이다.
Gradient vanishing 문제를 유발하던 가중치 행렬$W$의 곱셈이 일어나지 않는다!
수식으로 전개해보면 아래와 같다.

- 역전파 과정을 그림으로 나타내면 다음과 같다. Gradient flow가 직접적인 경로로 전달됨을 알 수 있다!

3.3 BPTT → Truncated BPTT
- 그리고 RNN 구조에서는 역전파를 할 때 BPTT방식을 사용한다. BPTT란 Backpropagation through time의 약자로, 순전파와 역전파를 모든 시간 단계에 통으로 적용하는 방법이다.
그림으로 나타내면 아래와 같다.

- 하지만 이러한 방법은 시간 단계가 길어질수록 계산량이 어마어마하게 많아지고, gradient exploding/vanishing문제도 발생한다.
이에 대한 해결방법으로 Truncated BPTT을 제안한다.
- Truncated BPTT을 적용하면 순전파는 모든 시간 단계에서 하지만, 역전파는 일정 시간 단계에서만 하게 된다.
그림으로 나타내면 아래와 같다.

- 이렇게 하면 계산량이 줄어들고 가중치 업데이트를 빠르게 할 수 있다. 그리고 gradient 문제들이 조금이나마 줄어든다.
하지만 장기 의존성을 학습할 수가 없다. 시간 단계 전체를 고려하지 않기 때문이다.
4. Interpretable cell 탐색
-RNN이 어떤 방식으로 정보를 처리하는지 이해하기 위해서 Interpretable cell 탐색을 사용할 수 있다.
- Interpretable cell 탐색은 아래와 같은 순서로 진행된다.
① 특정 은닉 상태 벡터 $h_{t}$의 한 요소를 선택한다.
② 입력 시퀀스를 모델에 통과시켜서 순전파를 한다.
③ 시간 단계별로 선택된 $h_{t}$의 값을 색으로 시각화해서 입력 데이터의 특정 부분이 네트워크에 어떻게 반영되는지 분석한다.
- 놀라운 점은, 다음 글자를 예측하도록만 학습시켰을 뿐인데 입력 데이터에서 유의미한 구조를 학습했다는 것이다!
아래의 예시처럼 문장의 길이를 인식할 수도 있고, 문장 안에서 quote나 comment를 인식할 수도 있다.


5. 적용 예시
5.1 CV
- Image Captioning
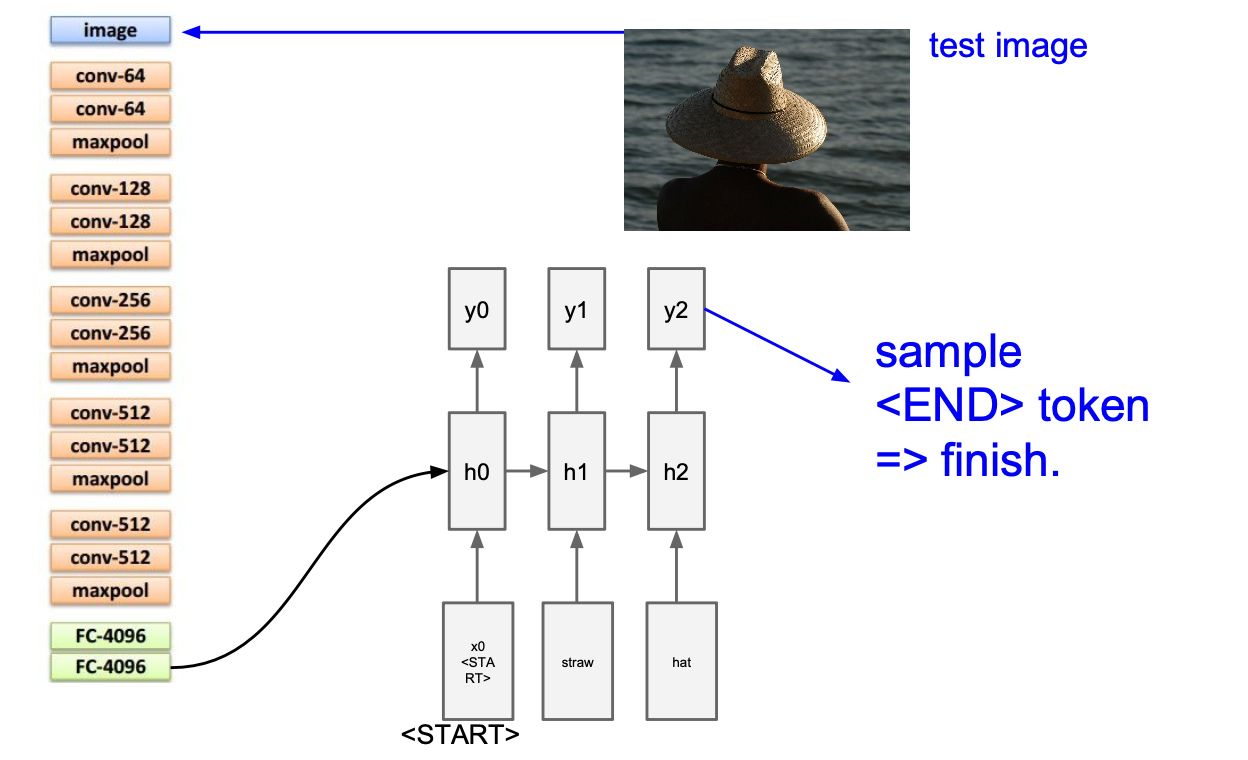
Example Results

Failure Cases

with Attention





- Visual Question Answering
5.2 NLP
Character-level Language Model Sampling
참고문헌
[1] Stanford University, "Lecture10, Recurrent Neural Networks ," YouTube, Aug. 12, 2017. [Online]. Available:
https://www.youtube.com/watch?v=6niqTuYFZLQ&list=PL3FW7Lu3i5JvHM8ljYj-zLfQRF3EO8sYv&index=10
[2] F. Li, J. Johnson, and S. Yeung, "CS231n Convolutional Neural Networks for Visual Recognition: Lecture 10- Recurrent Neural Networks," Stanford Univ., 2017. [Online]. Available:
https://cs231n.stanford.edu/slides/2017/cs231n_2017_lecture10.pdf
'기본기 다지기' 카테고리의 다른 글
| [CS] 비선형 자료구조(힙, 우선순위 큐, 맵, 셋, 해시테이블) (0) | 2024.12.17 |
|---|---|
| [CS231n] Lecture11: Detection and Segmentation (0) | 2024.11.29 |
| [CS] 인덱스 (1) | 2024.11.26 |
| [CS231n] Lecture9: CNN Architectures (1) | 2024.11.25 |
| [CS231n] Lecture8: Deep Learning Software (0) | 2024.11.23 |