Lecture7: Training Neural Networks II
- CS231n 강의 [1]를 듣고 공부한 내용을 나름대로 정리했다.
- 글에 있는 모든 그림, 표, 예시는 [2]에서 가져왔다.
~ 목차 ~
1. Optimization
1.1 First-Order Optimization
1.1.1 Problems with SGD
1.1.2 SGD + Momentum
1.1.3 Nesterov Momentum
1.1.4 AdaGrad
1.1.5 RMSProp
1.1.6 Adam
1.1.7 UsingLearning Rate Decay
1.2 Second-Order Optimization
1.2.1 L-BFGS
1.3 실제 학습에서는..2. Regularization
2.1 Add term to loss
2.2 Dropout
2.3 Data Augmentaion
2.3.1 Horizontal Flips
2.3.2 Random crops and scales
2.3.3 Color Jitter
2.3.4 Others
2.4 Common patterns
3. Model Ensembles
4. Transfer learning
1. Optimization
- Optimization은 loss function을 최소화하기 위해 수행한다.
어떤 미분계수를 사용하는가에 따라 first-order optimization과 second-order optimization으로 나눌 수 있다.
1.1 First-Order Optimization
- First-Order Optimization은 기울기를 사용해서 linear approximation을 한다.
그리고 아래 그래프와 같이 이 linear approximation을 최소화하는 방향으로 이동한다.

- First-order optimization의 종류로 SGD+Momentum, Nesterov Momentum, AdaGrad, RMSProp, Adam을 소개한다.
1.1.1 Problems with SGD
1.1.2 SGD + Momentum
1.1.3 Nesterov Momentum
1.1.4 AdaGrad
1.1.5 RMSProp
1.1.6 Adam
1.1.7 UsingLearning Rate Decay
1.2 Second-Order Optimization
- Second-Order Optimization은 기울기와 Hessian을 사용해서 quadratic approximation을 한다.
그리고 아래 그래프와 같이 이 quadratic approximation의 최솟값을 찾는 방향으로 이동한다.
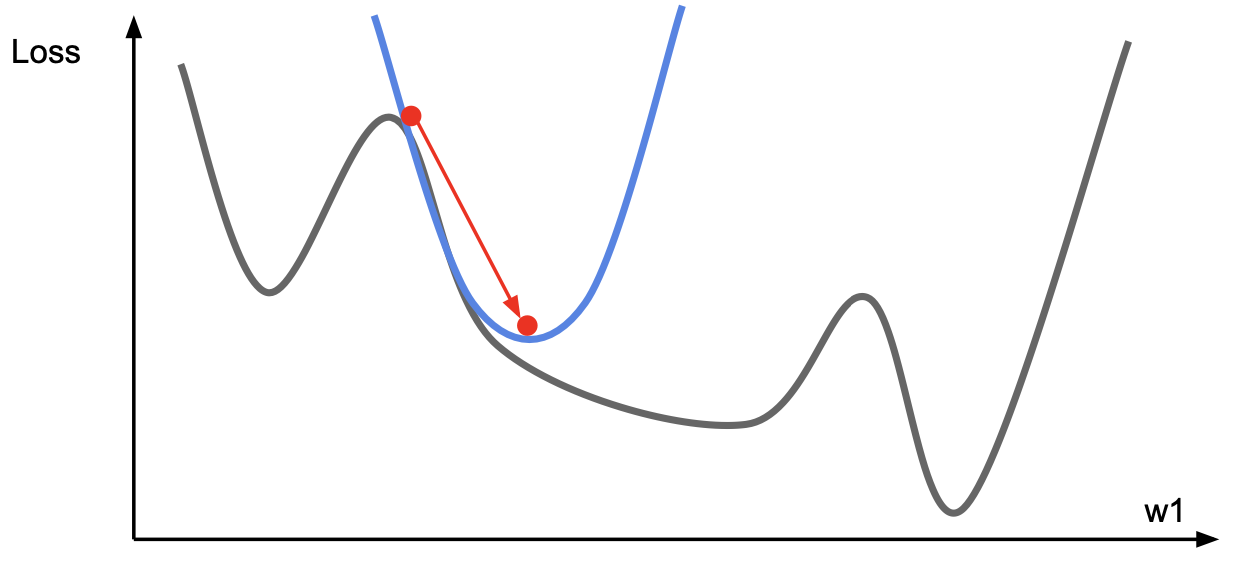
- Second-order Taylor expansion의 식은 아래와 같다.

- 그리고 여기서 critical point를 찾는 식은 아래와 같다.

- 장점: 수식을 보면 learning rate가 없다는 것을 알 수 있다. 최솟값을 구해서 바로 이동하기 때문에 learning rate가 필요하지 않다!
- 단점: 하지만 딥러닝에서 사용하기에는 계산비용이 너무 크다. Hessian계산은 시간복잡도 O($N^{2}$)이기 때문이다.
1.2.1 L-BFGS
- 계산비용이 너무 크다는 단점을 개선하기 위해 L-BFGS이 나왔다.
- L-BFGS는 Hessian을 전체 계산하지 않고 근사 계산하는 방법이다.
엄밀히 말하면 second-order optimization은 아니지만.. 사고의 흐름에 따라서 여기에 들어온 것 같다.
- 하지만 실제로는 많이 사용되지 않는다. Hessian의 근사계산이 stochastic한 것들에서 잘 작동하지 않기 때문이다.
(Style transfer와 같은 stochastic하지 않은, full batch를 사용하는 task에서는 사용되기도 한다.)
1.3 실제 학습에서는..
- 기본적으로 Adam을 사용하는 것이 좋다.
- Full batch update가 가능한 경우에서는 L-BFGS를 시도해보는 것도 좋다.
2. Regularization
- Single model의 성능을 올리기 위해서 다양한 regularization 기법들을 사용할 수 있다.
강의에서는 이러한 기법의 종류로 adding term to loss, dropout, data augmentation이 소개된다.
2.1 Add term to loss
- Adding term to loss는 이전의 lecture에서 나왔듯이 data loss 계산 뒤에 regularization항을 추가하는 것이다.
수식으로 표현하면 아래와 같고, 보통 L2 regularization이 사용된다.

2.2 Dropout
- Dropout는 아래 그림과 같이 순전파 과정에서 뉴런들을 설정한 비율만큼 임의로 drop해서 일시적으로 비활성화하는 방법이다.
하이퍼파라미터 값으로 dropout의 비율을 정할 수 있으며, 보통 0.5정도로 설정된다.

- 장점: 모델이 더 독립적이고 일반화된 특징을 학습하도록 유도할 수 있다.
아래 그림과 같이 여러 특징들을 학습한 모델들을 앙상블하는 것으로 이해할 수도 있다.(앙상블에 대한 설명은 뒤에 나옴)

-
2.3 Data Augmentaion
2.3.1 Horizontal Flips
2.3.2 Random crops and scales
2.3.3 Color Jitter
2.3.4 Others
2.4 Common patterns
3. Model Ensembles
- Model Ensemble은 학습할 때 여러 개의 모델을 학습시킨 뒤, test에서 그 결과들을 평균내는 방법이다.
이렇게 하면 성능을 2%정도는 올릴 수 있다.
- 여러 개의 모델을 학습시키지 않고 하나의 모델을 학습시킨 뒤 특정 epoch의 모델들을 가져와서 앙상블시켜도 된다.
이때 아래 그래프와 같이 Cyclic Learning Rate(CLR), 즉 주기적으로 learning rate를 조정해서 local minima를 다양하게 탐색하도록 유도할 수 있다.

- Polyak averaging이라는 방법을 사용할 수도 있다. 각 epoch에서 나온 모델의 파라미터를 사용하는 대신, 학습 과정 전체에서 나온 파라미터 벡터의 moving average를 사용하는 방법이다.
코드로 구현하면 아래와 같다.

4. Transfer learning
- Transfer Learning은 전이학습으로, 새로운 데이터셋을 학습시킬 때 이미 학습된 모델을 활용하는 방법이다.
- 기존의 "You need a lot of data if you want to train/use CNNS"라는 고정관념을 깬다.
많은 데이터가 필요 없다. 적은 데이터(심지어 1,000개 이하)로도 CNN을 학습시킬 수 있다!
- Transfer learning의 방법은 아래 그림과 같다.

① 먼저 ImageNet과 같은 대규모 데이터셋으로 pre-trained된 모델을 가져온다.
② 그다음 내가 훈련시키고 싶은 데이터셋을 특정 층에서만 학습시키고, 나머지 층들은 freeze 해놓는다.
이를 fine-tuning이라고 한다.
Fine-tuning 할 때는lr을 기존보다 작게($\frac{1}{10}$정도)로 하는 것이 좋다.
- 아래 표는 훈련 데이터셋의 크기와 데이터셋의 유사도에 따른 행동지침이다.

- 학습하려는 데이터가 적지만 기존 모델의 데이터와 비슷할 때, top layer에서 linear classifier를 사용하면 된다.
- 학습하려는 데이터가 적고 기존 모델의 데이터와도 전혀 다를 때, 쉽지 않다.. Linear classifier를 곳곳에서 사용하면서 지켜봐야 한다.
- 학습하려는 데이터가 많고 기존 모델의 데이터와 비슷할 때, 적당한 개수의 층을 fine tuning하면 된다.
- 학습하려는 데이터가 많고 기존 모델의 데이터와 전혀 다를 때, 꽤 많은 개수의 층을 fine tuning해야 한다.
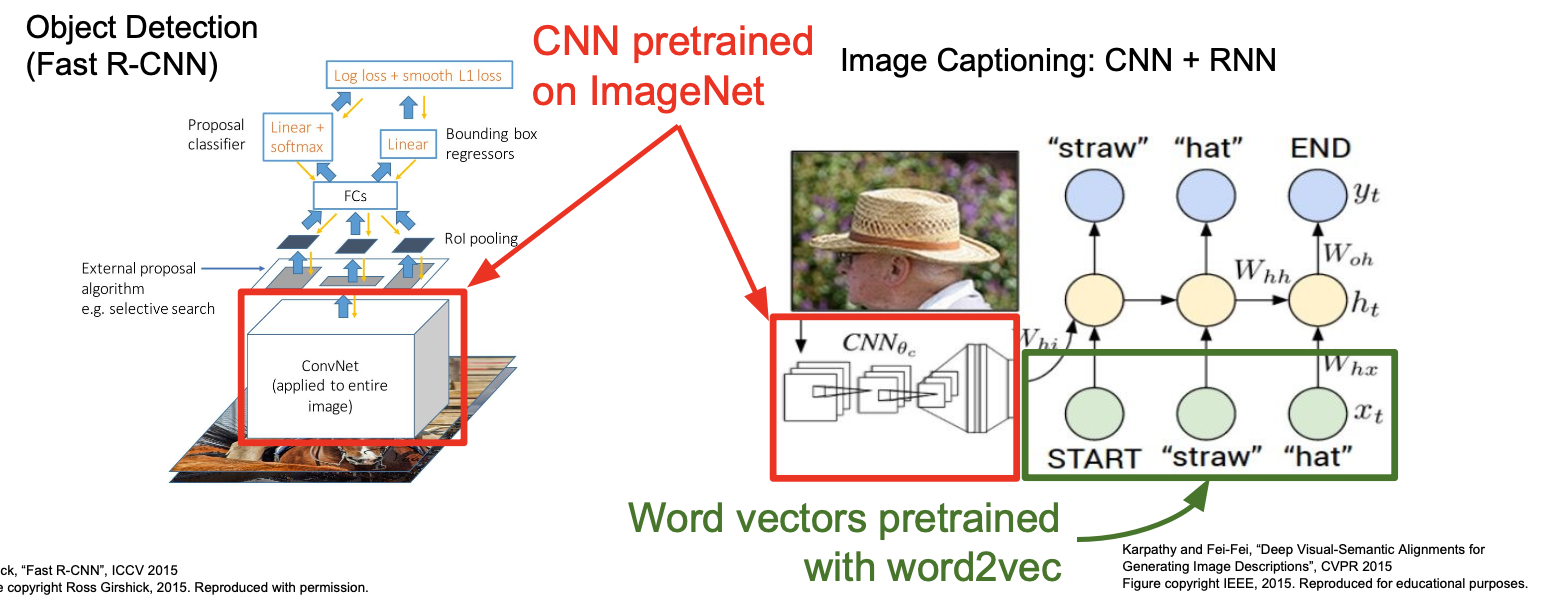
- CNN에서 전이학습은 정말 많이 사용된다.
아래 그림과 같이 object detection task와 image captioning task에서는 ImageNet으로 pretrained된 CNN이 사용된다.
추가로 image captioning task에서는 word2vec으로 pretrained된 word vector가 사용되기도 한다.
- 다음 시간에는 Deep Learning Software에 대해서 배울 것이다.
참고문헌
[1] Stanford University, "Lecture7, Training Neural Networks II," YouTube, Aug. 12, 2017. [Online]. Available:
https://www.youtube.com/watch?v=_JB0AO7QxSA&list=PL3FW7Lu3i5JvHM8ljYj-zLfQRF3EO8sYv&index=7
[2] F. Li, J. Johnson, and S. Yeung, "CS231n Convolutional Neural Networks for Visual Recognition: Lecture 7-Training Neural Networks II," Stanford Univ., 2017. [Online]. Available:
https://cs231n.stanford.edu/slides/2017/cs231n_2017_lecture7.pdf
'기본기 다지기' 카테고리의 다른 글
| [CS231n] Lecture9: CNN Architectures (1) | 2024.11.25 |
|---|---|
| [CS231n] Lecture8: Deep Learning Software (0) | 2024.11.23 |
| [CS231n] Lecture6: Training Neural Networks I (0) | 2024.11.21 |
| [CS231n] Lecture5: Convolutional Neural Networks (0) | 2024.11.20 |
| [CS231n] Lecture4: Introduction to Neural Networks (0) | 2024.11.19 |