Lecture9: CNN Architectures
- CS231n 강의 [1]를 듣고 공부한 내용을 나름대로 정리했다.
- 글에 있는 모든 그림, 표, 예시는 [2]에서 가져왔다.
~ 목차 ~
1. 주요 모델들
1.1 AlexNet
1.2 VGG
1.3 GoogLeNet
1.4 ResNet
1.5 모델 비교2. 그 외 모델들
2.1 NiN (Network in Network)
2.2 Improved model of ResNet2.3 Wide ResNet
2.4 ResNeXT
2.5 Stochastic Depth
2.6 FractalNet
2.7 DenseNet
2.8 SqueezeNet
1. 주요 모델들
- 주요 모델인 AlexNet, VGGNet, GoogLeNet, ResNet을 소개한다.
1.1 AlexNet
- AlexNet은 ILSVRC-2012에서 1등을 하면서 CNN의 부흥을 일으킨 모델이다.
- 아래 그림과 같이 conv layer 5개와 fc layer 3개로 이루어져 있다.
그리고 2개의 GPU를 이용해서 데이터를 반반씩 학습시켰다. 3번째 conv layer와 fc layer들에서만 GPU끼리 소통을 한다.
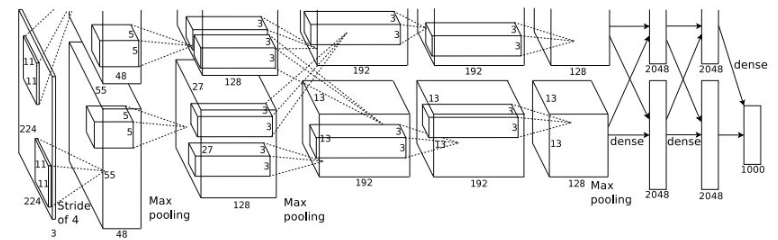
- 정규화 방법으로 처음으로 ReLU를 도입했고, LRN이라는 방법을 사용했고(지금은 안 쓰지만),
data augmentation과 dropout도 적용했다.
- 모델 구조를 보면서 output volume size와 파라미터 수를 계산해보면 계산 감을 잡을 수 있다. 강의에서 몇 가지 예제를 제시한다.
Q1: 1번째 레이어(CONV1)의 output volume size?
- 이미지 크기는 227x227x3이고, 11x11 필터가 stride=4로 96개 있으므로
필터가 한 줄에서 (227-11)/4 + 1 = 55번 작동하므로, output volume size는 55x55x96이다.
Q2: 1번째 레이어(CONV1)의 파라미터 수?
- (11x11x3)x96개
Q3: 2번째 레이어(POOL1)의 output volume size?
- CONV1를 통과한 이미지 크기는 55x55x96이고, 3x3 필터가 stride=2로 96개 있으므로
필터 (55-3)/2 + 1 = 27번 작동하므로, output volume size는 27x27x96이다.
Q4: 2번째 레이어(POOL1)의 파라미터 수?
- 0개. Pooling layer에는 파라미터가 없다.
1.2 VGG
- VGGNet은 AlexNet을 기반으로 모델을 더 깊게 쌓아서 ILSVRC-2014의 localization task 1등, classification task 2등을 했다.
아래 그림은 AlexNet과 VGG-16, VGG-19의 구조를 보여준다.
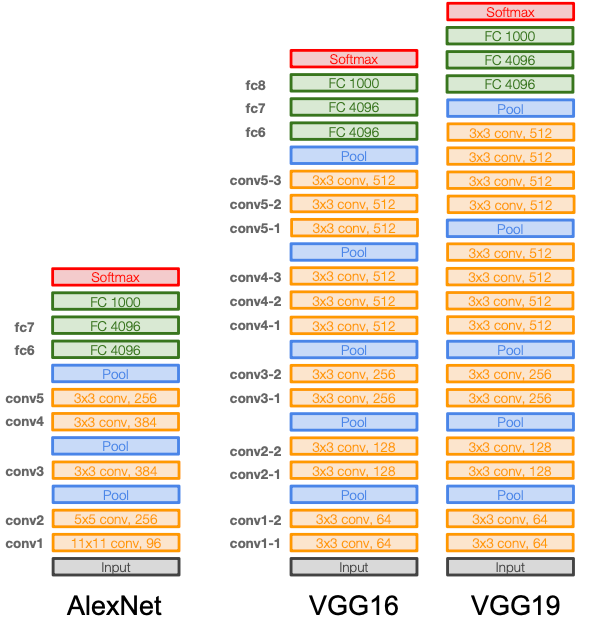
- VGG-16과 VGG-19는 3x3크기의 작은 필터를 이용해서 모델을 총 16-19층으로 쌓았다.
이렇게 작은 크기의 필터를 사용하면 파라미터 수를 줄이고 계산 효율성을 높일 수 있다.
3x3 필터 2개를 연속으로 사용하면 5x5 필터와 receptive field이 같지만, 파라미터 수는 훨씬 적다.
그리고 3x3 필터 3개를 쌓으면 7x7 필터와 같은 receptive field 효과를 낼 수 있다.
1.3 GoogLeNet
- VGGNet은 ILSVRC-2014 classification에서 우승을 한 모델로, inception module을 여러 개 사용해서 22층으로 쌓았다.
파라미터 수가 AlexNet의 1/12밖에 안 될 정도로 효율적이다.
- Inception module은 다양한 크기의 필터(1x1 3x3 5x5 conv, 3x3 pooling)를 병렬적으로 사용해서 다양한 스케일의 정보를 추출한다.
아래 그림은 naive한 inception module의 구조이다.

- 하지만 이렇게만 하면 아래 그림과 같이 계산량이 엄청나게 커진다. (854M ops)
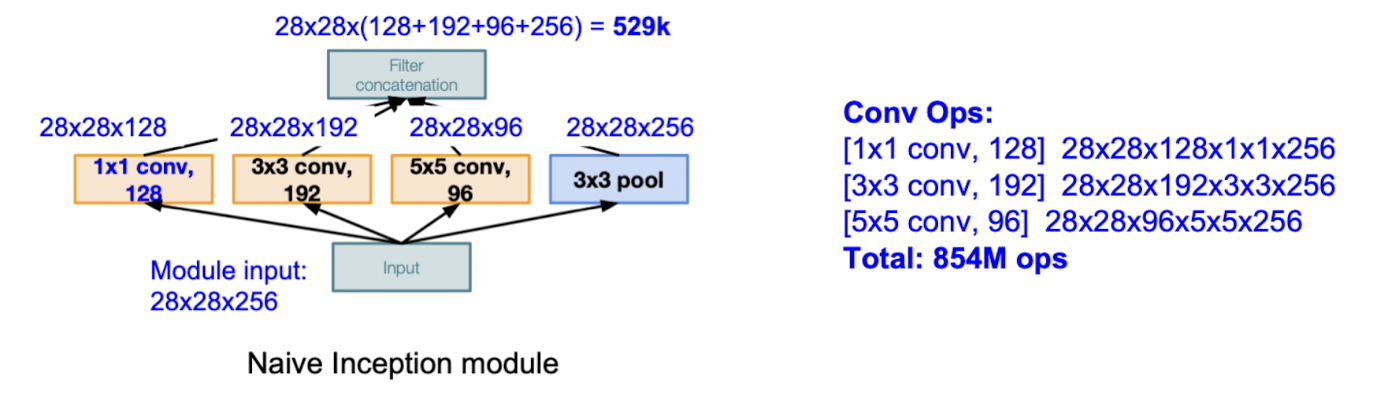
- 그래서 중간중간에 1x1 conv layer를 적절하게 배치해서 차원을 줄여 계산량을 줄인다. (358M ops)

- 최종적인 모델 구조는 아래와 같다.

1.4 ResNet
- ResNet은 residual connection을 이용해서 모델을 152층까지 쌓아 ILSVRC-2015에서 top-5 error 3.57%를 기록했다.
이는 human performance를 넘는 기록이다!
- Plain layer에서는 레이어가 깊어질수록 train error와 test error가 높게 나타난다는 문제가 있었다.
오버피팅의 문제는 아니다. Test error뿐만 아니라 train error도 높게 나오기 때문이다.

- 그래서 깊은 모델의 최적화의 어려움 때문이라는 가설을 세운다.
가설을 바탕으로 H(x)을 직접 학습하지 않고 대신 잔차 F(x)(=H(x)-x)를 학습하도록 하는 해결책을 제시한다.
그림으로 나타내면 아래와 같다.

- 이렇게 했더니 문제가 해결되었다!
잔차학습을 사용하니 깊은 모델의 train error가 더 낮게 나왔고, 모델을 152층까지 쌓는 데에 성공했다.
- 전체적인 모델 구조는 아래와 같다. 2개의 3x3 conv layer마다 residual connection이 붙는다.
Conv layer를 다 거치고 난 뒤 average pooling을 거치고 바로 분류용 fc 1000 layer로 들어간다. 다른 fc layer는 없다.

- ResNet-34는 위 그림과 같이 2개의 conv layer(3x3, 3x3)마다 residual connection이 붙지만,
ResNet-50 이상은 3개의 conv layer(1x1, 3x3, 1x1)마다 residual connection이 붙는다.
이러한 구조를 bottleneck 구조라고 부르고, 계산 효율을 높이고 깊은 층에서도 정보 손실을 최소화 할 수 있다.

1.5 모델 비교
- 아래 그래프를 보면 ILSVRC-2012에서 AlexNet의 우승을 시작으로 점점 모델이 깊어지면서 성능이 좋아졌음을 알 수 있다.
ILSVRC-2015에서 우승한 ResNet-152는 top-5 error 3.57%을 기록하면서 휴먼에러를 넘어섰다.

- 아래 왼쪽 그래프를 보면 Inception-v4(ResNet + Inception)의 top-1이 가장 높다.
- 아래 오른쪽 그래프는 x축을 연산량(operation), y축을 top-1 accuracy, 그리고 원의 크기를 메모리 사용량으로 한다.
- VGG 모델들이 메모리 사용량과 연산량이 가장 많다.
- GoogLeNet이 가장 효율적이다. (∵성능대비 메모리 사용량이 적음)
- AlexNet이 다른 모델들에 비해서 계산량은 작지만 top-1 accuracy가 낮고 메모리 사용량도 많다.
- ResNet은 모델에 따라서 효율성도 적당하고 다른 모델들에 비해 top-1 accuracy가 높은 편이다.

- 아래 그래프는 모델별 순전파 소요시간과 전력 소비량을 나타낸다.
순전파 소요시간은 BN-AlexNet과 BN-NIN이 가장 작고, VGG 모델들이 가장 크다.
전력 소비량은 배치 사이즈가 어느정도 커지면 GoogLeNet이 가장 작다.

2. 그 외 모델들
- 위의 4개 모델들 외에 알아두면 좋은, inspiration을 얻을 수 있는 모델들을 소개한다.
2.1 NiN (Network in Network)
- NiN은 micronetwork, 즉 1x1 conv layer를 활용해서 추상적인 특징들을 추출한다.
아래 구조(b)처럼 conv layer 자체가 1x1 conv layer로 구성된 mlpconv layer이다.
- GoogLeNet과 ResNet의 bottleneck layer 아이디어의 바탕이 된 모델이고, 특히 GoogLeNet Inception의 기반이 되었다.

2.2 Improved model of ResNet
- ResNet 논문 저자들이 후속연구를 통해서 ResNet 구조를 발전시켰다.
원래 발표된 ResNet은 $y=ReLU(BN(F(x))+x)$와 같은 구조였지만,
아래 그림과 같은 $y=BN(ReLU(F(x)))+x$ 구조로 수정하면서 성능을 높였다.

2.3 Wide ResNet
- Wide ResNet은 모델의 깊이를 늘리는 것보다 residual block의 폭을 넗히는 게 더 중요하다고 주장했다.
Residual block의 폭을 넓히기 위해서 아래 그림과 같이 필터 개수를 F개가 아니라 Fxk개로 설정했다.

- 그 결과, WideResNet-50이 그냥 ResNet-152보다 성능이 좋았다.
2.4 ResNeXT
- ResNeXT는 ResNet 논문 저자들의 후속 연구이다.
아래 그림과 같이 cardinality(residual block의 폭을 병렬 경로 여러 개를 사용해서 증가시킴) 방식을 사용한다.
- Inception과 비슷한 아이디어(병렬 경로)를 기반으로 한다.

2.5 Stochastic Depth
- Stochastic Depth는 vanishing gradient 문제를 줄이고 학습시간을 줄이기 위해 도입되었다.
- Train에서는 아래 오른쪽 그림과 같이 랜덤하게 레이어를 드롭시키고, test에서는 왼쪽 그림과 같이 모델 전체를 사용한다.
학습 시 드롭되는 레이어는 identity function으로 대체된다.

2.6 FractalNet
- FractalNet은 아래 그림과 같은 fractal구조(네트워크 안에서 여러 경로가 중첩된 형태)를 사용한다.
얕은 경로는 빠른 정보 흐름을, 깊은 경로는 복잡한 표현을 학습한다.
- 이러한 fractal 구조를 사용하면 residual representation이 필수적이지 않다고 주장한다.
- Train에서는 sub-path들을 드랍하고, test에서는 모델 전체를 사용한다.

2.7 DenseNet
- DenseNet은 아래 그림과 같이 각 층이 순전파 방향에 있는 다른 층과 모두 연결되어 있다.
이렇게 하면 vanish gradient 문제를 완화하고, feature들이 전파가 잘 되고 재사용하기도 좋아진다.

2.8 SqueezeNet
- SqueezeNet은 아래 그림과 같이 1x1필터로 squeeze하는 층과 1x1과 3x3 필터로 expand하는 층으로 구성되어 있다.
이렇게 하면 특징을 효율적으로 추출할 수 이고 계산비용을 줄일 수 있다.
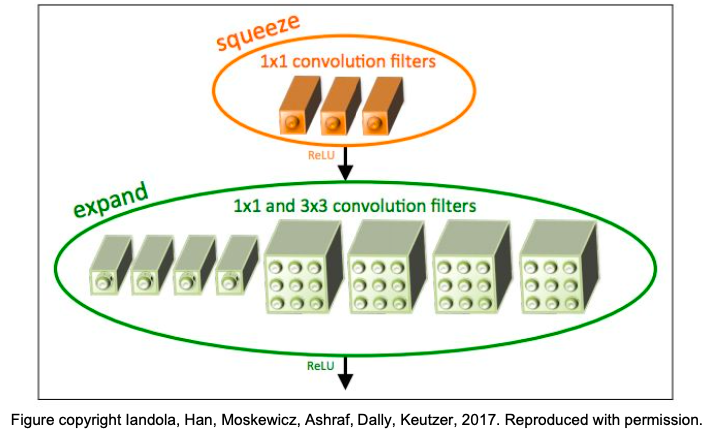
- 파라미터 수가 AlexNet의 1/50이 되지만 ImageNet에서의 정확도는 비슷하게 나온다.
그리고 모델크기를 0.5MB(AlexNet의 1/510)로 압축할 수도 있다.
- 다음 시간에는 Recurrent Neural Networks에 대해서 배울 것이다.
참고문헌
[1] Stanford University, "Lecture9, CNN Architectures," YouTube, Aug. 12, 2017. [Online]. Available:
https://www.youtube.com/watch?v=DAOcjicFr1Y&list=PL3FW7Lu3i5JvHM8ljYj-zLfQRF3EO8sYv&index=9
[2] F. Li, J. Johnson, and S. Yeung, "CS231n Convolutional Neural Networks for Visual Recognition: Lecture 9- CNN Architectures," Stanford Univ., 2017. [Online]. Available:
https://cs231n.stanford.edu/slides/2017/cs231n_2017_lecture9.pdf
'기본기 다지기 > CS231n' 카테고리의 다른 글
| [CS231n] Lecture11: Detection and Segmentation (0) | 2024.11.29 |
|---|---|
| [CS231n] Lecture10: Recurrent Neural Networks (수식o) (0) | 2024.11.27 |
| [CS231n] Lecture8: Deep Learning Software (0) | 2024.11.23 |
| [CS231n] Lecture7: Training Neural Networks II (1) | 2024.11.22 |
| [CS231n] Lecture6: Training Neural Networks I (0) | 2024.11.21 |