VGGNet 논문리뷰
이번 논문리뷰는 VGGNet 논문이다 [1].
(K. Simonyan and A. Zisserman, "Very Deep Convolutional Networks for Large-Scale Image Recognition," Proc. Int. Conf. on Learning Representations (ICLR), 2015.)
논문 제목은 Very Deep Convolutional Networks for Large-Scale Image Recognition이다.
(+ VGG는 옥스퍼트 대학교의 연구그룹 Visual Geometry Group에서 나온 이름이다.)
~ 목차 ~
0. Abstract
1. Introduction
2. ConvNet 구성
2.1 구조
2.2 구성
2.3 논의
3. ConvNet 학습과 평가
3.1 학습
3.2 평가
3.3 기타 구현 방법
4. 실험 결과
4.1 Single Scale 평가
4.2 Multi-Scale 평가
4.3 Multi-Crop 평가
4.4 ConvNet 앙상블
4.5 SOTA와의 비교
5. Conclusion
0. Abstract

- 이 논문에서는 conv network의 깊이가 대규모 image recognition 환경에 미치는 영향에 대해서 연구한다.
- 주요 내용: 3x3 크기의 conv filter를 사용하면서 모델 깊이를 점점 늘린 결과, 16-19층까지 늘리는 데 성공함
→ 엄청나게 성능이 향상됨
1. Introduction

- ConvNet 구조가 보편화되면서 사람들은 AlexNet의 구조를 발전시켜서 성능을 높이려는 다양한 시도를 했는데,
이 논문에서는 ConvNet의 깊이에 초점을 두었다.
- 마지막에는 다른 파라미터를 고정시켜두고 conv layer만 추가하면서 모델의 깊이를 계속 늘리는 시도를 했다.
이는 3x3 크기의 아주 작은 conv filter를 사용하기에 가능한 시도였다.
* 보통 image recognition 작업에서는 복잡한 전처리와 후처리가 이루어지는데 이거 없이도 좋은 성능을 냄
→ VGGNet이 단순한 파이프라인으로도 강력한 특징을 추출한다는 뜻
2. ConvNet 구성

- ConvNet 깊이 증가에 따른 효과만 확인할 수 있도록 CNN,AlexNet논문의 ConvNet구성을 그대로 사용했다.
2.1 구조

- 224x224 크기의 이미지가 들어온다.
- 레이어 종류
① Conv layer
- 3x3크기 필터를 사용한다. (cf. 일부 모델에는 1x1필터도 있는데 이건 그냥 입력이미지 선형변환임)
* 사용 이유: 젤 작은 필터이기 때문 (1x1은 방향정보 포착 불가, 2x2는 중간픽셀이 없어서 상하좌우 구분 불가)
- Conv stride=1, Conv padding=1 (∵conv layer 크기 3x3을 유지하기 위해)
- 뒤에 ReLU가 붙음
② Max-pooling layer
- 총 5개, 일부 conv layer 뒤에 위치함
- Max-pooling 크기=2x2, Max-pooling stride=2
③ FC layer
- 총 3개 (1·2번째는 채널 4096개, 마지막은 채널 1000개)
- 뒤에 ReLU가 붙음
④ Softmax layer
2.2 구성

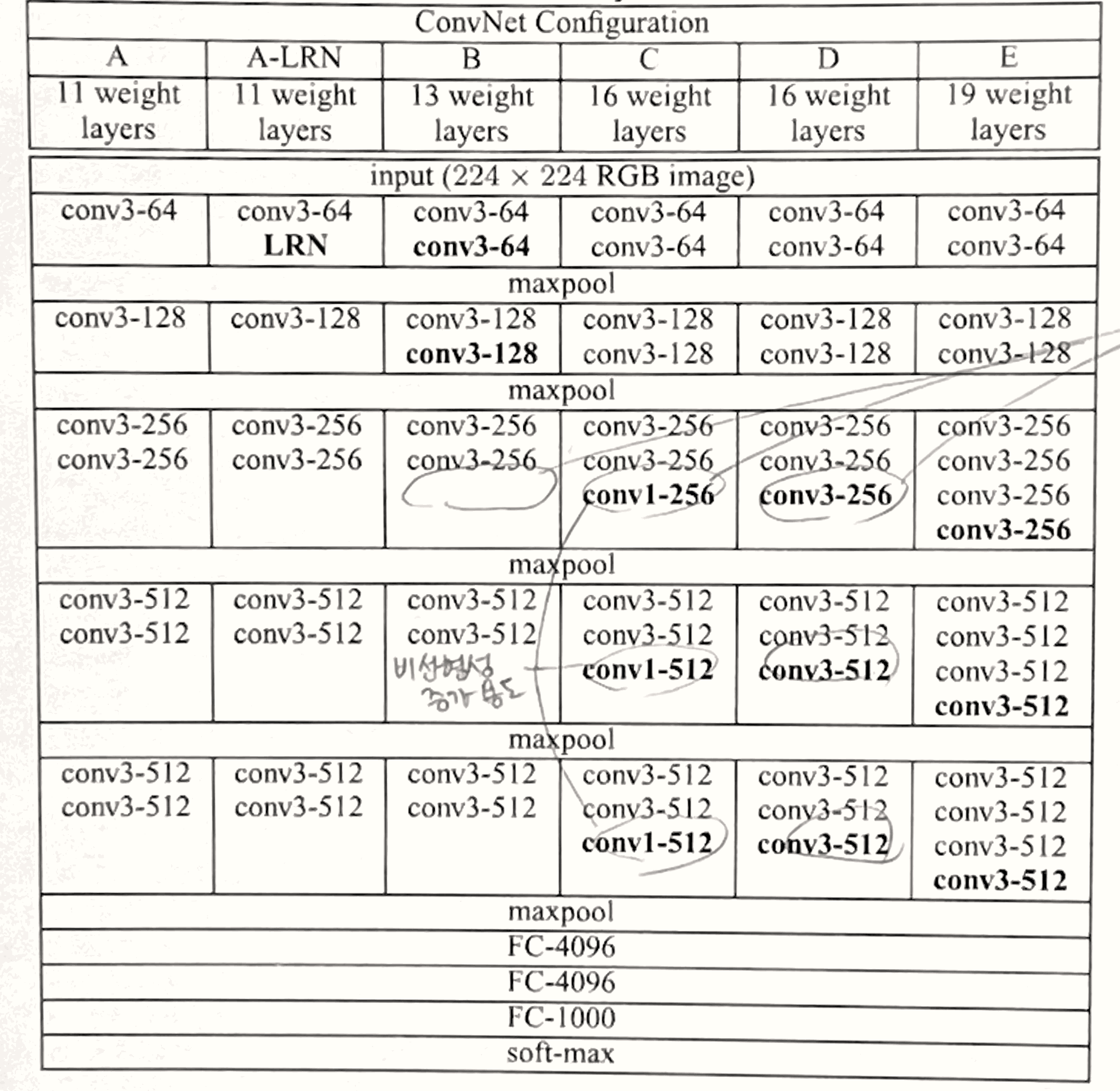

- ConvNet 구성
- 깊이에 따라서 A-E로 이름을 붙였다.
- 깊이 11-19, 너비 64-512(2의제곱들)
- 파라미터 수
- VGG19가 얕지만 넓은 모델(Sermanet et al., 2014)보다 파라미터 수가 많지 않다.
2.3 논의

- ILSVRC-2012하고 2013의 탑모델들은 1번째 conv layer에서 상대적으로 큰 필터를 사용했지만,
VGGNet은 모델 전체에서 3x3 크기의 아주 작은 필터가 입력 이미지의 모든 픽셀을 촘촘하게 지나가도록 했다.
- 3x3 필터 2개를 사용하면 5x5와 같은 효과를 내고, 3개를 사용하면 7x7과 같은 효과를 낸다.
- 7x7 1개 대신 3x3 3개 사용해서 얻는 효과
① ReLU가 3개가 들어가게 되기 때문에 결정함수가 더 뚜렷해진다.
② 파라미터 수가 줄어든다.
- C모델에서는 1x1 필터도 사용되는데, 이는 ReLU만 추가되는 것이므로 결정함수가 더 뚜렷해진다.
3. ConvNet 학습과 평가
3.1 학습

- 학습과정은 AlexNet과 비슷하지만, 여기서는 multi-scale 모델을 사용한다.
- 수렴까지 에폭이 AlexNet보다 적게 돌았다! (74 epoch)
→ 추측이유: 작은 필터와 깊은 구조가 정규화 효과를 일으켰기 때문?
아니면 특정 레이어를 미리 초기화해뒀기 때문일수도?
- Mini-batch size 256, Momentum 0.9, L2정규화 $5 * {10}^{-4}$, Dropout 0.5,
lr: ${10}^{-2}$에서 val acc 지지부진 할 때마다 ${10}^{-1}$씩 곱해짐 (총 3번)
- 가중치 초기화가 중요하기 때문에 가장 얕은 모델 A부터 시작해서 여러 초기화 시도를 해봤는데,
논문을 제출하고 나서 Xavier초기화의 존재를 알게 되었다..
- 학습할 이미지 크기 S를 정하는 방법에는 2가지가 있다.
① Single-scale training
- 여기서는 S=256, S=384를 사용했다.
- S=384를 학습시킬 때는 속도를 내기 위해서
우선 모델을 S=256으로 학습시킨 뒤, 256의 가중치들로 초기화하고 $lr$도 ${10}^{-3}$으로 작게 했다.
② Multi-scale training
- $S_{max}$와 $S_{min}$만 설정해주고 이 범위 안에서 랜덤하게 스케일링되게 한다.
- Multi-scale모델 학습을 시킬 때는 속도를 내기 위해서
우선 모델을 S=384로 학습시킨 뒤, 이 single-scale모델을 multi-scale모델로 파인튜닝했다.
3.2 평가

- 순서
① 비율 맞춰서 이미지를 Q로 rescale 한다.
- 학습에서의 이미지 크기 S와 테스트에서의 이미지 크기 Q는 달라도 된다. (오히려 성능 향상될수도)
② Rescale된 이미지에 dense하게, 즉 신경망을 겹치게 적용한다.
- fc(connected) 레이어를 fc(convolutional) 레이어로 바꾼 뒤, 이미지 전체에 적용한다.
③ 그럼 class score map이 나온다.
- Class score map의 채널 개수는 클래스 개수만큼 나옴
④ 나온 class score map을 sum-pooling한다.
⑤ 원본 이미지하고 좌우반전된 이미지에 ①-④를 적용한 뒤 둘을 평균내서 최종 판단을 내린다.
- Test단계에서는 이미지가 fully convolutional(connected(x)!) 레이어를 통과하기 때문에
굳이 multi-crop를 하지 않아도 된다. 하지만 고민이 되는데.. 이유는
multi-crop이 계산량은 많지만 정확도는 더 높을 수도 있고, dense evaluation을 보완할 수 있기 때문이다.
(그래서 고민 끝에 평가해보긴 했음. 결과는 뒤에 나옴)
3.3 기타 구현 방법

- 기존의 C++ Caffee toolbox를 많이 바꿔서 사용했다.
(∵멀티GPU 적용하기 위해, 다양한 크기의 이미지 사용하기 위해)
- 단순한 방법으로 NVIDIA Titan Black GPU 4개를 활용해서 단일 GPU보다 3.75배 빠른 시스템을 구축했다.
4. 실험 결과

- ILSVRC-2012의 데이터셋을 사용했다.
- Train 130만장, val 5만장, test 10만장
↳ 학습에 사용되지 않은 클래스(held-out class labels)가 포함됨
4.1 Single Scale 평가

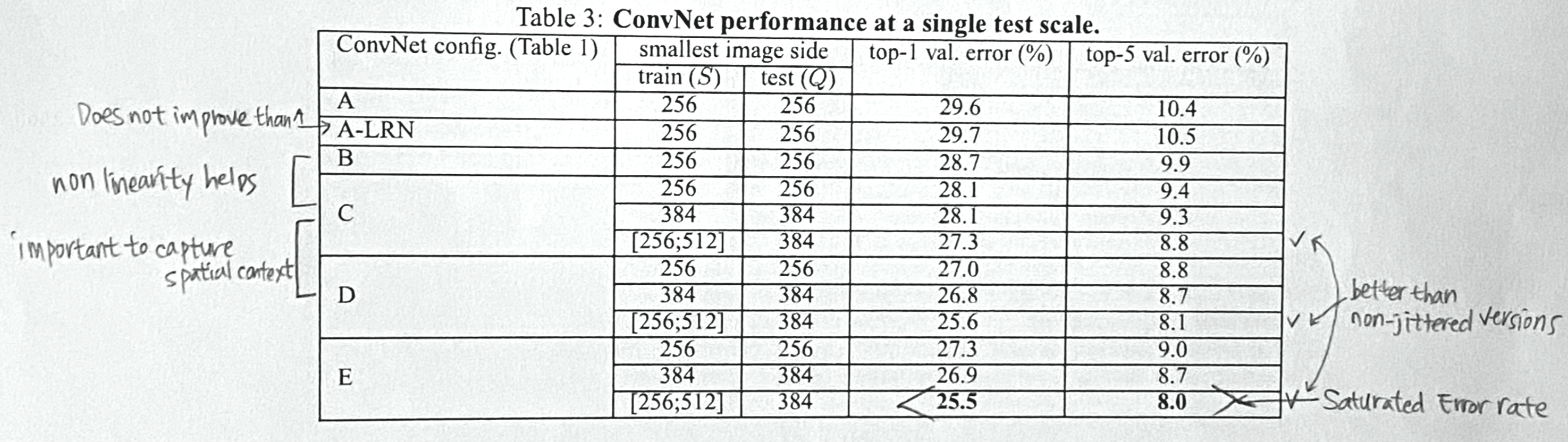
- Test 이미지 사이즈 Q는
(i) S가 고정일 때: Q = S이고,
(ii) S가 scale jittered 되었을 때: Q = $S_{min}$과 $S_{max}$의 평균이다.
- LRN이 성능 향상에 도움이 되지 않았다. → 이제 LRN 사용 안 함
- 1x1보다는 3x3이 성능 향상에 도움이 되었다. (∵capture spatial contexts)
- 19층에서 error가 포화된다. (cf. 더 큰 데이터셋으로 하면 좀 더 깊이 쌓을 수 있을지도?)
- 큰 필터로 얕게 쌓는 것보다 작은 필터로 깊게 쌓을 때 성능이 더 잘 나온다.
4.2 Multi-Scale 평가

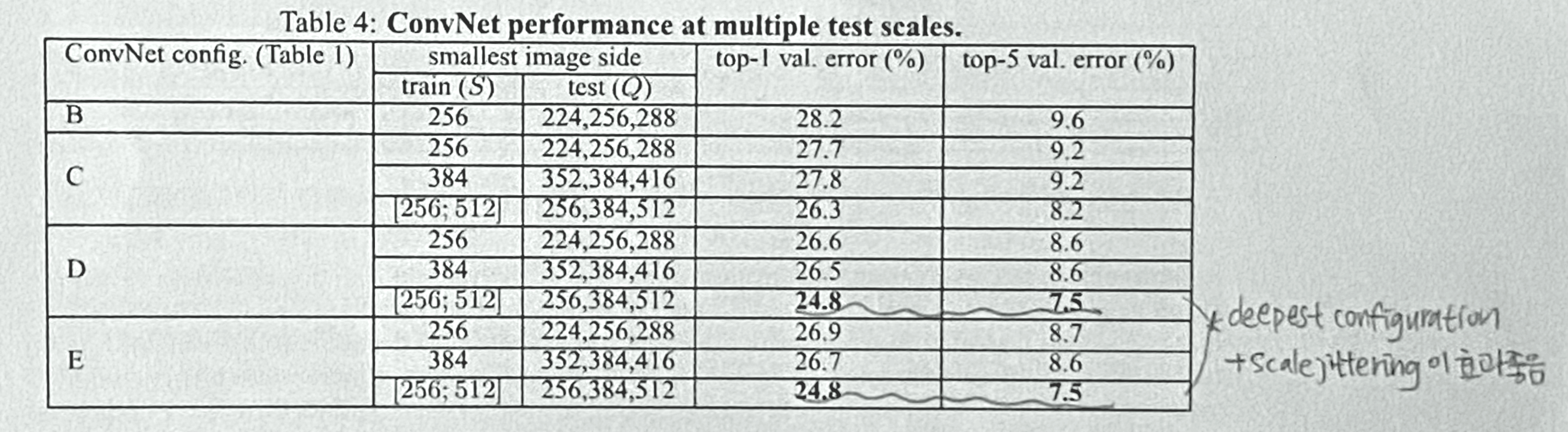
- 모델에 여러 개의 rescale된 이미지들을 돌린 뒤 그 결괏값들을 평균내서 평가를 한다.
(Fixed S는 {S-32, S, S+32}, Variable S는 {$S_{min}$, 0.5($S_{min}$+$S_{max}$), $S_{max}$})
- Scale jittering이 적용되었을 때, 그리고 깊이가 깊을수록 성능이 잘 나왔다.
4.3 Multi-Crop 평가

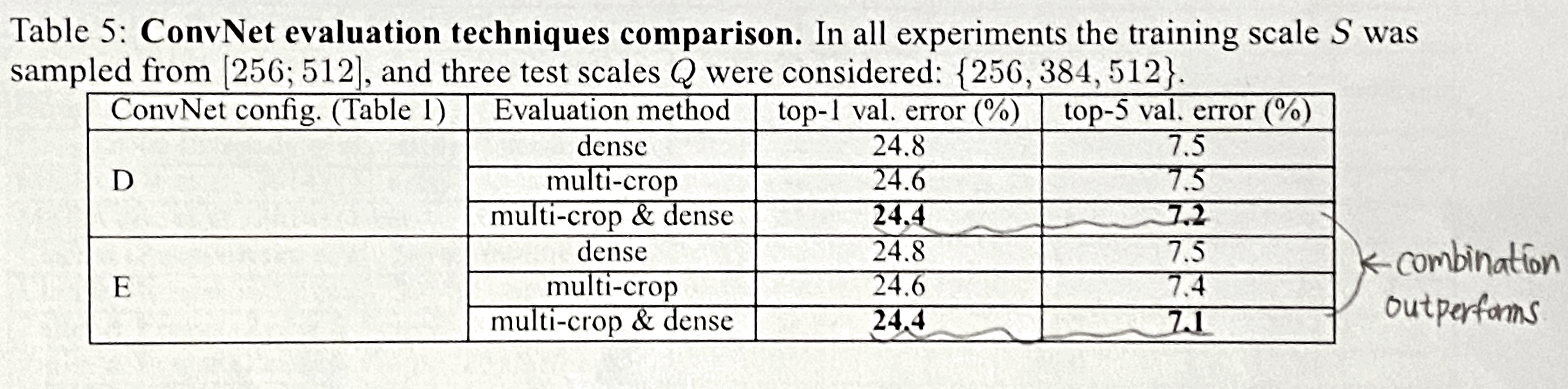
- 성능: Combined > multi-crop > dense
→ Combined가 가장 결과가 좋은 것을 보면 multi-crop과 dense eval이 상호보완됨을 알 수 있다.
4.4 ConvNet 앙상블


- 앙상블도 해봤다.
→ 탑 모델 2개(D,E)를 앙상블하고, multi-crop과 dense eval을 모두 사용했을 때 성능이 가장 좋게 나왔다.
(top-5 test error 6.8%)
4.5 SOTA와의 비교

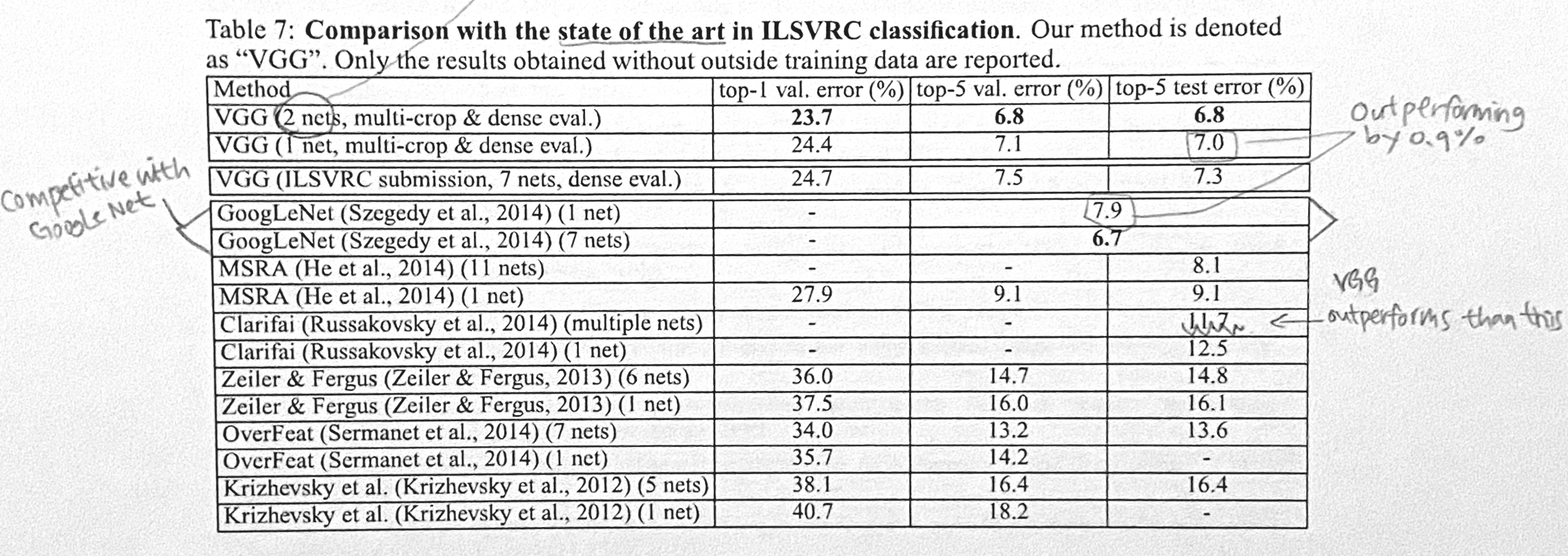
- VGG는 모델 2개만 앙상블해서 좋은 성능을 냈다.
기존의 ConvNet구조에서 벗어나지도 않았다. 모델을 더 깊게 쌓은 것 밖에 없다!
5. Conclusion

- 기존 ConvNet구조를 더 깊게 쌓으면 성능 향상시킬 수 있다.
깊이의 중요성을 끝까지 강조하면서 논문이 마무리된다.
(Appendix는 생략)
끝~!
참고문헌
[1] K. Simonyan and A. Zisserman, "Very Deep Convolutional Networks for Large-Scale Image Recognition," Proc. Int. Conf. on Learning Representations (ICLR), 2015.
'Paper Review > CNN' 카테고리의 다른 글
| [논문리뷰] Deep Residual Learning for Image Recognition (ResNet) (1) | 2024.11.15 |
|---|---|
| [논문리뷰] Imagenet classification with deep convolutional neural networks (AlexNet) (1) | 2024.11.12 |