설문지 응답 검출 프로그램 제작(with Python)
~ 목차 ~
1. 개요
1.1 기간
1.2 TASK
1.3 문제점
1.4 목표
2. 데이터
2.1 구성
2.2 특징
3. 프로세스
4. 이슈와 해결방법
4.1 bbox 위치·크기 설정의 애매함
4.2 응답 색의 다양함
4.3 과하게 연한 응답 존재
5. 결과
6. 회고
1. 개요
1.1 기간
- 총 3일 (24.7.30. - 24.8.1.)
1.2 TASK
- 학과 대학원 연구실에서 설문지로 진행한 설문조사의 응답을 전산상에 입력해야 했다.
1.3 문제점
- 기존에는 응답 데이터를 사람이 수기로 입력했는데, 문항에 비례하여 시간이 소요된다는 단점이 있었다.
1.4 목표
- 시간을 절약하기 위해 설문지에서 응답을 자동으로 검출하는 프로그램을 만드는 것을 목표로 했다.
2. 데이터
2.1 구성
- 총 66,000문항으로, 사람이 수기로 입력하기 쉽지 않은 양이다.
(설문지당 문항 수: 330문항 (5지선다형), 응답자: 200명)
2.2 특징
- 데이터 형식이 jpg, pdf으로 섞여있었다.
- 종이 설문지에 응답이 다양한 필기구로 체크되어 있었다.
- 스캔 과정에서 비뚤어진 상태로 스캔된 설문지들이 있었다.
3. 프로세스
- 전체 프로세스는 아래 그림과 같다. 여러 형식의 설문지가 있었고, 이 중 한 형식을 예시로 들어보겠다.
각 형식마다 bbox의 위치와 크기만 다르게 설정해주었다.

① 이미지 전처리
- 설문지를 불러온 다음 형식을 PDF에서 jpg로 변경한다.
- 과하게 틀어진 설문지들은 방향을 수동 조정해줬다.
- 한 페이지에 2쪽이 스캔된 설문지는 잘라서 한 페이지에 1쪽만 있게끔 크기를 맞춰주었다.
② bbox 설정
- 선택지의 위치마다 bbox를 설정한다.
- bbox의 크기와 위치는 과정②,③을 반복하면서 실험적으로 설정되었다.
- 크기: 16x16
- 위치: 설문지가 조금씩 틀어져서 스캔되었기 때문에,
bbox의 위치는 응답을 최대한 많은 경우를 아우를 수 있도록 미세조정되었다.
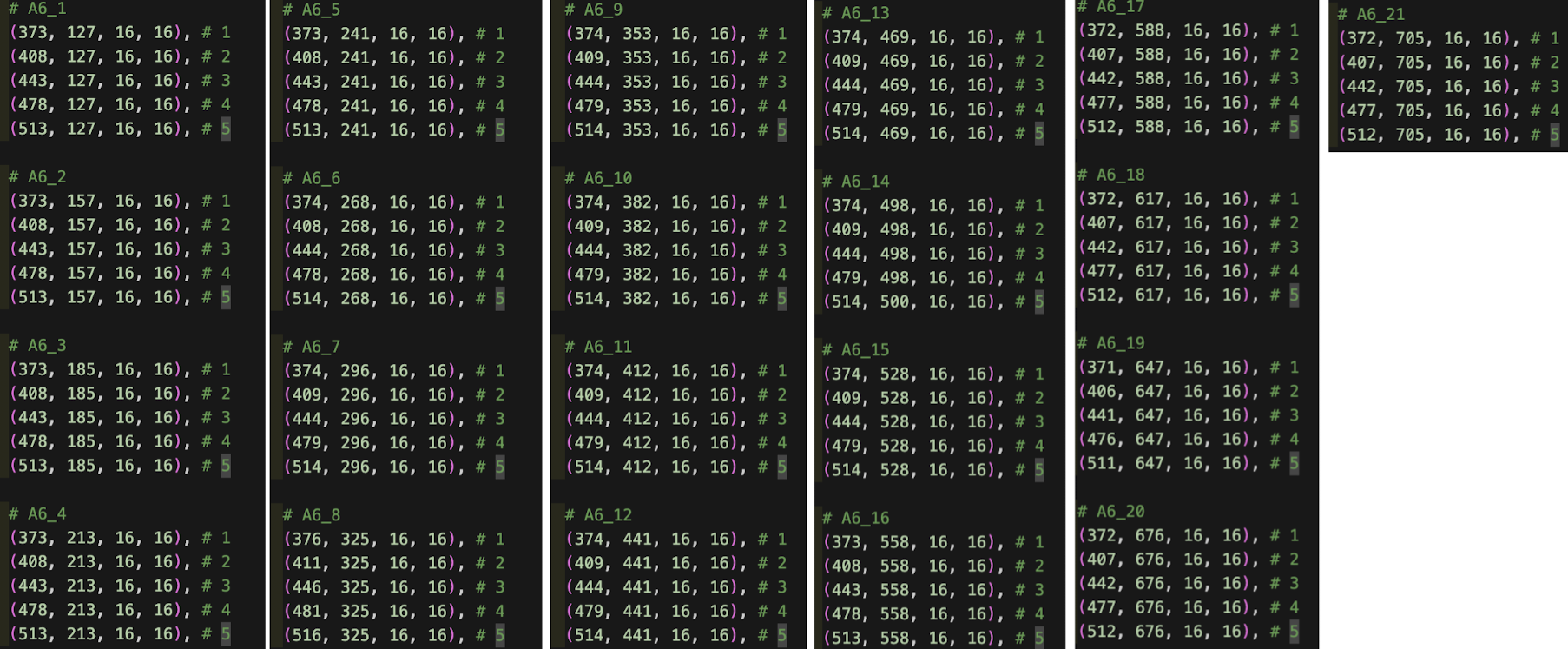
③ 그룹 설정
- 같은 질문에 대한 선택지들을 그룹화한다.
(∵과정④에서 그룹 안에서 비교하기 위해)
→ 그룹 1개에 선택지 1,2,3,4,5가 포함되고, 총 21개의 그룹이 생성된다.
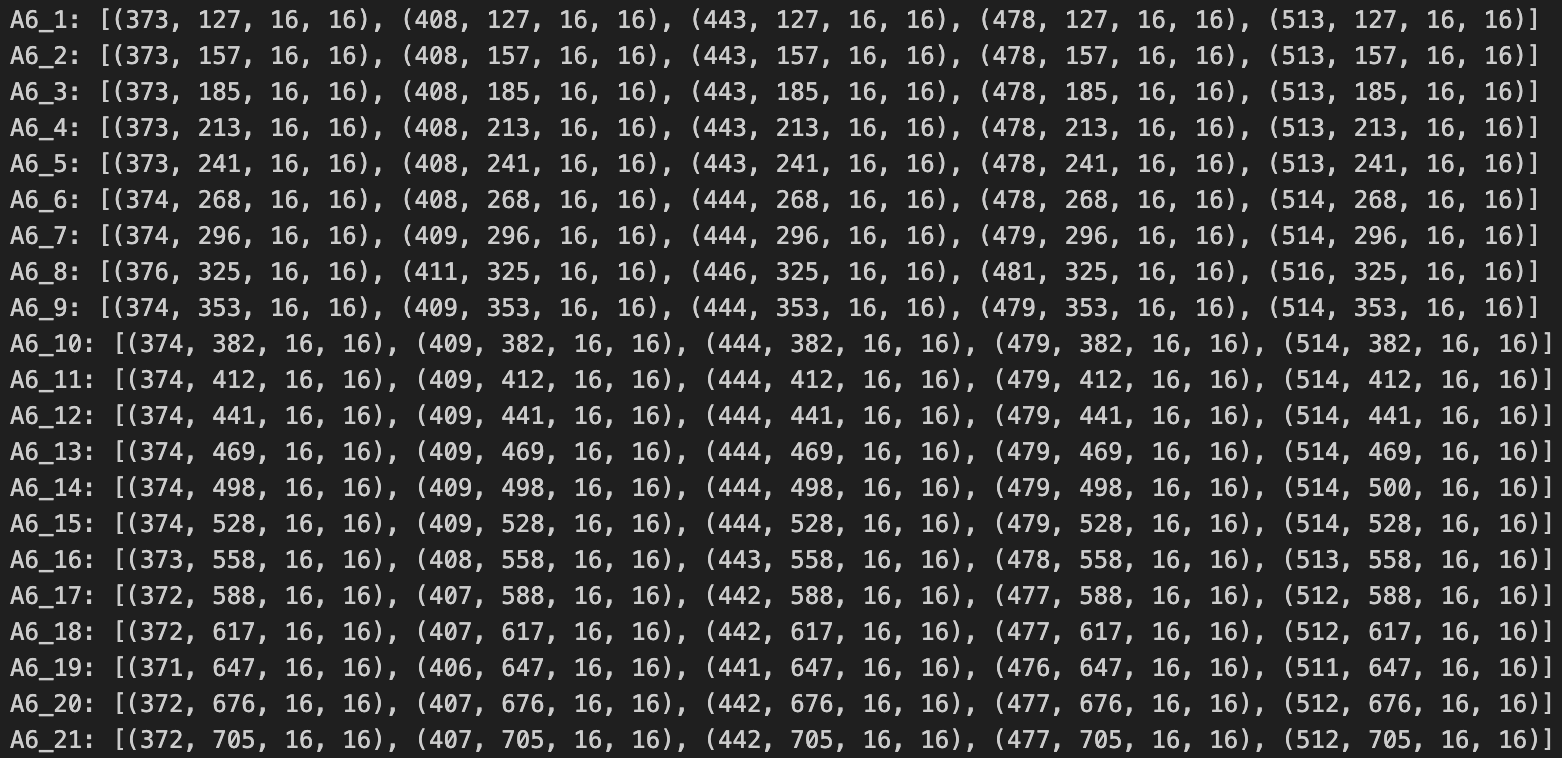
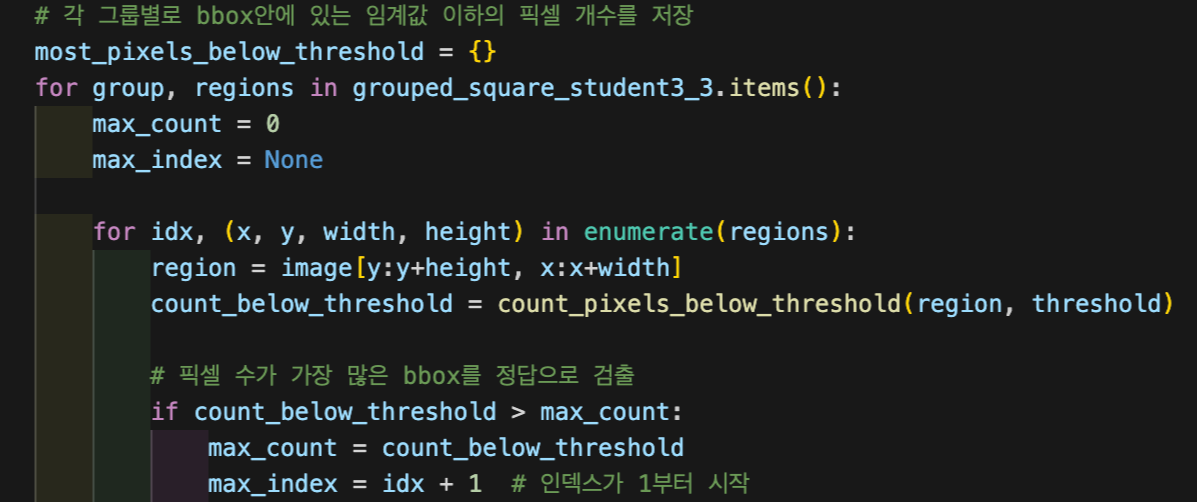
④ 검출
- 픽셀의 RGB 임계값을 설정한다.
- RGB 임계값도 실험적으로 설정되었다(230, 230, 230).
- 각 그룹별로 bbox 안에 임계값 이하의 픽셀이 몇 개 들어있는지 검출한다.
- 각 그룹별로 임계값 이하의 픽셀이 가장 많이 들어있는 bbox를 정답으로 인식한다.
⑤ 과정①~④ 반복
- 같은 형식의 설문지마다 과정①~④를 반복했다.
4. 이슈와 해결방법
4.1 bbox 위치·크기 설정의 애매함
- 잘못 체크한 응답에 'X' 표시를 한 설문지들 28개 존재했다. 이 경우 과정④의 정답 도출 단계에서 문제가 생긴다.
임계값 이하의 픽셀이 많아짐에 따라 'X'표시를 한 응답이 정답으로 인식되기 때문이다.
→ 해결방법: 검출 결과를 보면서 직접 수정해주었다.
- 칸의 크기보다 응답의 크기가 큰 설문지들이 13개 존재했다. 이 역시 과정④의 정답 도출 단계에서 문제가 생긴다.
응답이 다른 칸들을 과도하게 침범하기 때문에 임계값 이하의 픽셀 수를 세는 것이 무의미해지기 때문이다.
→ 해결방법: 검출 결과를 보면서 직접 수정해주었다.
- 스캔 과정에서 오류가 난 설문지가 1개 존재했다. 이 경우에도 과정④의 정답 도출 단계에서 문제가 생긴다.
설문지의 선택지 위치와 bbox의 위치가 대응되지 않기 때문이다.
→ 해결방법: 검출 결과를 보면서 직접 수정해주었다.
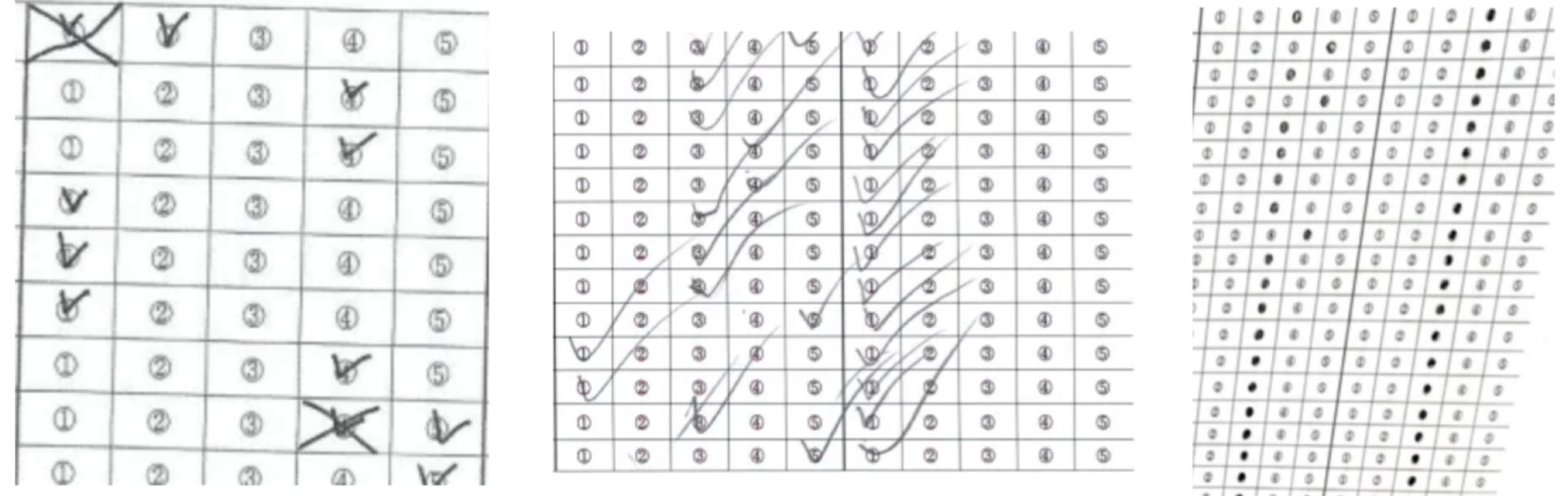
4.2 과하게 연한 응답 존재
- 응답하지 않은 설문지와 과하게 연하게 응답한 설문지가 존재했다.
이 경우 과정④의 임계값 설정 단계에서 문제가 될 수 있다.
- 임계값은 (255,255,255)일 때 흰 픽셀까지 모두 검출되고 작아질수록 점점 검은 픽셀이 검출된다.
과도하게 연한 응답들을 검출하기 위해 임계값을 (245,245,245)으로 설정해본 결과,
연한 응답들은 검출이 되었지만 다른 설문지들에서는 검출정확도가 떨어지는 문제가 발생했다.
아무래도 임계값이 (255,255,255)에 가까워질수록 노이즈가 발생하기 때문인 것으로 보인다.
→ 해결방법: 과하게 연하게 응답된 설문지들의 응답들을 직접 수정해줬다.
임계값을 (230,230,230)으로 했을 때 전체적인 검출정확도가 가장 높게 나왔기 때문이다.
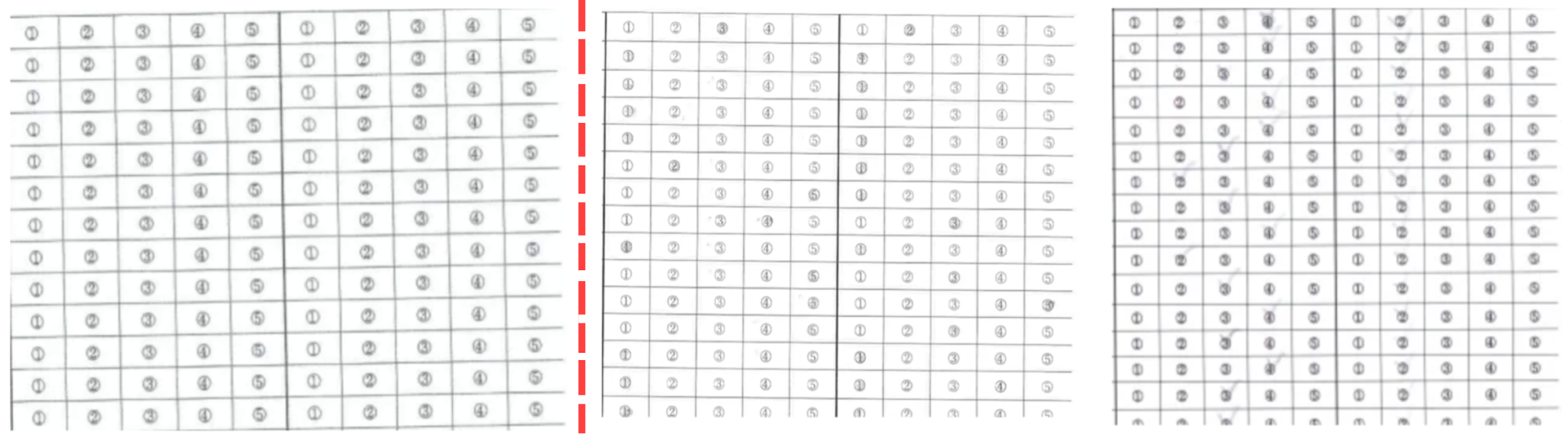
4.3 응답 색의 다양함
- 빨간색 펜, 보라색 하이라이터 등 다양한 색깔의 도구로 응답을 한 설문지가 존재했다.
이 경우 과정④의 임계값 설정 단계에서 문제가 될 수 있다.
→ 해결방법: 이미지 전체를 흑백 처리 한 다음 4.2에서 설정한 임계값 (230,230,230)을 적용하니
모두 성공적으로 검출되었다.

5. 결과
- 4.3까지 진행한 결과 약 96.127%의 정확도를 냈다. (63,444 / 66,000)
6. 회고
- 결론적으로 말하자면.. 마지막에 66,000개의 응답 결과를 직접 확인하는 과정을 거쳤다.
가장 큰 이유는 다른 사람의 연구에 쓰이는 데이터이기 때문에 정확도 100%가 보장되어야 했기 때문이다.
내가 만든 프로그램이지만 정확도 100%가 나올 거라는 확신을 하지는 못했다.
직접 확인해본 결과 약 96.127%의 정확도를 냈고, 에러는 설문지가 틀어져서 스캔되어 발생된 것으로 보였다.
- 자동으로 문서를 정방향으로 맞춰주는 라이브러리를 뒤늦게 발견했다.
이를 사용했으면 bbox의 미세 조정 작업이 필요하지 않았을 것이고, 에러도 0%에 수렴했을 것이다.
다음에는 꼭 기존에 라이브러리가 있는지 미리 확인해봐야겠다. 아니면 직접 만들어서라도 사용해야겠다.
- 종이 설문을 진행항 때 같은 도구를 사용해서 같은 모양으로 마킹하도록 하면 좋을 것 같다.
(새삼 왜 OMR 마킹할 때 원을 꼼꼼히 채우라고 하는지, 왜 어느정도 진하게 칠하라고 하는지 이해가 되었다.)
- 추후에 이 프로젝트를 발전시킨다면 직접 수정하는 방법보다 더 나은 해결방법을 찾아보고 싶다.
- 간단하지만 문제 정의부터 목표 수립, 프로세스 구성, 이슈 처리까지의 모든 과정을 주체적으로 경험할 수 있었다.
'프로젝트 > 토이프로젝트' 카테고리의 다른 글
| [토이프로젝트] 쌓기나무 프로그램 구현 (중간보고) (0) | 2024.11.28 |
|---|---|
| [토이프로젝트] 쌓기나무 프로그램 구현 (계획수립) (1) | 2024.11.24 |